Scala编程初级实践-统计学生成绩_scala统计学生成绩-程序员宅基地
Scala编程初级实践
统计学生成绩
学生的成绩清单格式如下所示,第一行为表头,各字段意思分别为学号、性别、课程名1、课程名2等,后面每一行代表一个学生的信息,各字段之间用空白符隔开
Id gender Math English Physics
301610 male 80 64 78
301611 female 65 87 58 …给定任何一个如上格式的清单(不同清单里课程数量可能不一样),要求尽可能采用函数式编程,统计出各门课程的平均成绩,最低成绩,和最高成绩;另外还需按男女同学分开,分别统计各门课程的平均成绩,最低成绩,和最高成绩。
- 样例一
Id gender Math English Physics
301610 male 80 64 78
301611 female 65 87 58
301612 female 44 71 77
301613 female 66 71 91
301614 female 70 71 100
301615 male 72 77 72
301616 female 73 81 75
301617 female 69 77 75
301618 male 73 61 65
301619 male 74 69 68
301620 male 76 62 76
301621 male 73 69 91
301622 male 55 69 61
301623 male 50 58 75
301624 female 63 83 93
301625 male 72 54 100
301626 male 76 66 73
301627 male 82 87 79
301628 female 62 80 54
301629 male 89 77 72
- 结果

- 样例二
Id gender Math English Physics Science
301610 male 72 39 74 93
301611 male 75 85 93 26
301612 female 85 79 91 57
301613 female 63 89 61 62
301614 male 72 63 58 64
301615 male 99 82 70 31
301616 female 100 81 63 72
301617 male 74 100 81 59
301618 female 68 72 63 100
301619 male 63 39 59 87
301620 female 84 88 48 48
301621 male 71 88 92 46
301622 male 82 49 66 78
301623 male 63 80 83 88
301624 female 86 80 56 69
301625 male 76 69 86 49
301626 male 91 59 93 51
301627 female 92 76 79 100
301628 male 79 89 78 57
301629 male 85 74 78 80
-
结果
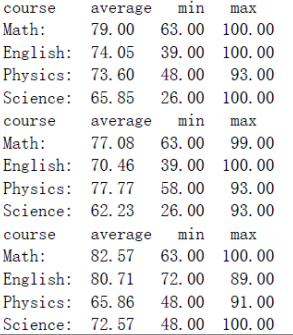
-
代码如下
import scala.collection.mutable.ArrayBuffer
object Student_core {
//把所有的成绩都放在数组里 分为三个数组 array1 不分男女 array2 male .... 筛选数据
def get_alldata(array1:ArrayBuffer[Int],array2:ArrayBuffer[Int],array3:ArrayBuffer[Int]){
for(i <- 2 to courseNames.length+1){
for (j<- 0 to allStudents.length-1){
array1.append(allStudents(j)(i).toInt)
}
}
for(i <- 2 to courseNames.length+1){
for (j<- 0 to allStudents.length-1){
if(allStudents(j)(1)=="male"){
array2.append(allStudents(j)(i).toInt)
}
}
}
for(i <- 2 to courseNames.length+1){
for (j<- 0 to allStudents.length-1){
if(allStudents(j)(1)=="female"){
array3.append(allStudents(j)(i).toInt)
}
}
}
}
def get_data(array:ArrayBuffer[Int],data:ArrayBuffer[Double],data2:ArrayBuffer[Double],Nn:Int){
while (!array.isEmpty){
for (i <-0 to Nn.toInt-1){
//用data来存储每个学科的成绩 存取的长度刚好是每一个学科的所有成绩
data.append(array(i))
}
array.trimStart(Nn) //删除array里已经保存过的每学科成绩
data2.append((data.sum/data.length).formatted("%.2f").toDouble)
data2.append(data.min.formatted("%.2f").toDouble)
data2.append(data.max.formatted("%.2f").toDouble)
data.trimEnd(Nn) //清空data
}
}
def print_data(data:ArrayBuffer[Double]){
for (i<-0 to courseNames.length-1){
print(courseNames(i)+": ")
for(j<-0 to 2){
print(data(j)+" ")
}
println()
data.trimStart(3)
}
}
/**
Id gender Math English Physics Science
301610 male 72 39 74 93
301611 male 75 85 93 26
301612 female 85 79 91 57
301613 female 63 89 61 62
301614 male 72 63 58 64
301615 male 99 82 70 31
301616 female 100 81 63 72
301617 male 74 100 81 59
301618 female 68 72 63 100
301619 male 63 39 59 87
301620 female 84 88 48 48
301621 male 71 88 92 46
301622 male 82 49 66 78
301623 male 63 80 83 88
301624 female 86 80 56 69
301625 male 76 69 86 49
301626 male 91 59 93 51
301627 female 92 76 79 100
301628 male 79 89 78 57
301629 male 85 74 78 80
**/
val File = scala.io.Source.fromFile("d:/2.txt")
val all_Data = File.getLines().map{
_.split(" ")}.toList
val courseNames = all_Data.head.drop(2) //拿到课程名
courseNames(0)="Math "
val allStudents = all_Data.tail
def main(args: Array[String]): Unit = {
val array1=ArrayBuffer[Int]() //所有成绩数据 只有成绩
val array2=ArrayBuffer[Int]() //male的所有成绩
val array3=ArrayBuffer[Int]()
get_alldata(array1,array2, array3)
val data=ArrayBuffer[Double]()
val data2=ArrayBuffer[Double]()//data2是保存所有平均值,最小值,最大值的数组
val Nn=(array1.length/courseNames.length)//Nn是一列数据的长度 不分男女 就是 60/3=20 male 就是42/3=13 female就是7
val male_data2=ArrayBuffer[Double]()
val male_Nn=array2.length/courseNames.length
val female_data2=ArrayBuffer[Double]()
val female_Nn=array3.length/courseNames.length
get_data(array1,data,data2, Nn)
get_data(array2,data,male_data2,male_Nn)
get_data(array3,data,female_data2,female_Nn)
println("course "+"average "+"min "+"max ")
print_data(data2)
println("course "+"average "+"min "+"max(male) ")
print_data(male_data2)
println("course "+"average "+"min "+"max(female) ")
print_data(female_data2)
}
}
运行结果输出如下
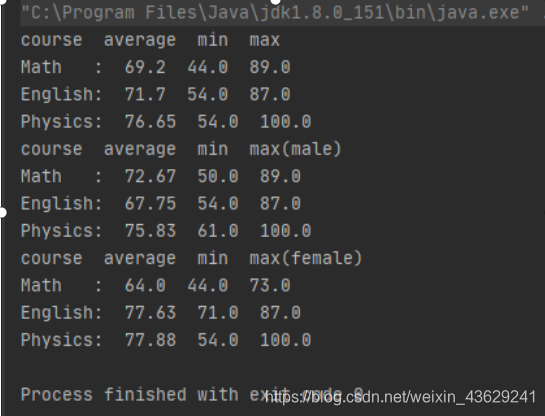
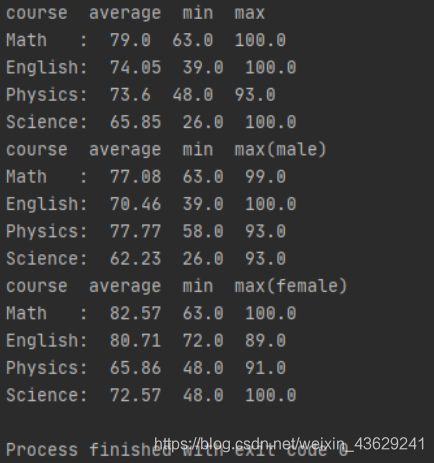
智能推荐
TRACCAR支持的设备列表-程序员宅基地
文章浏览阅读1.7k次。GT06_traccar支持的设备
基于连接的每IP限速实现_netfilter限速-程序员宅基地
文章浏览阅读9.7k次,点赞2次,收藏2次。在《修改netfilter的limit模块实现基于单个ip的流量监控》中,介绍了一种方式实现针对一个网段每个IP地址的流量控制,如果细化到流,那个就叫做针对每个流的流量控制,我们知道,一个IP地址可以和很多流相关联,针对流的流控限制的不是主机,而是主机上的一个连接,它的约束要比针对IP地址的流控更加小。 然而如何来实现这个呢?实际上在Linux中,几乎所有的流控都可以用TC工具配置出_netfilter限速
Java 获取linux根目录下的文件夹_java获取指定文件夹下的所有文件名-程序员宅基地
文章浏览阅读1.8k次。原文链接:java获取指定文件夹下的所有文件名_tomorrowzm的专栏-程序员宅基地_java查询指定文件夹下的所有文件输出文件名 site:blog.csdn.netblog.csdn.netpackage 这里我们主要使用的是listFiles函数来得到file文件夹下的所有文件,包括文件夹。然后通过File类的isFile和isDirectory来区分,如果是文件,就输出对应的信息,如..._java读取linux服务器下指定目录下的文件名称
Update批量更新(高性能、动态化)_批量update-程序员宅基地
文章浏览阅读7.6k次,点赞7次,收藏20次。文章目录前言一、环境开发环境测试环境二、灵光乍现MyBatis-Plus源码2.初见真正的批量更新语法三、开工基础类搭建SysUser(表sys_user实体类)Stash(拼接SQL服务,内部类)TableCacheDTO(数据表信息存储)TableCache(表信息缓存)MySQL拼接常量类缓存数据库表信息1. 继承AbstractMethod2. 自定义sql注入器3. 自定义注入器生效事务工具类制作SQL工具类SQL执行类四、测试100条测试数据1千条测试数据1万条测试数据10万条测试数据五、弊端总_批量update
PID优化系列之目标值平滑(斜坡函数梯形图+完整SCL代码)_控制斜坡pid-程序员宅基地
文章浏览阅读2.2k次,点赞4次,收藏6次。作为PID系列专题,这些文章,我都会给出PLC梯形图的源代码和SCL代码方便大家对比学习,文章中的错误和不严谨之处,也请大家指正。1、专题1:设定值响应问题 2、PLC的梯形图代码,这部分我们可以做成功能块,启用PID运算时,我们可以对设定值进行线性化平滑处理,也可以不处理。......_控制斜坡pid
编程实现36进制和10进制之间的相互转换_36进制转换10进制-程序员宅基地
文章浏览阅读1w次,点赞3次,收藏4次。36进制转换成10进制的方法,以R9和10Y为例R9就是 27 * 36^1 + 9*36^0 = 98110Y 就是 1* 36^2 + 0 * 36^1 + 34*36^0 =133010进制转换成36进制的方法,以1079和52360为例(1079/36^0) % 36 = 35(1079/36^1) % 36 = 29(1079/36^2) 所以_36进制转换10进制
随便推点
MDK配置jlink仿真器步骤_mdk5如何定义swd-程序员宅基地
文章浏览阅读5.5k次。MDK配置jlink仿真器步骤:1.如下图2.设置为SW模式3.选择处理器的flash大小4.设置utilities5.查看是否是SW模式6.查看Flash大小重新编译程序download就好了..._mdk5如何定义swd
渗透测试17---Metasploit (MSF) 部署与功能_msf war包部署 渗透-程序员宅基地
文章浏览阅读7.5k次。MetasploitMetasploit Framework简称MSF(ruby语言开发的)实验环境准备Metasploit的使用第一次使用要进行数据库的初始化msfdb init用的时候就:msfconsole也可以:msfdb run (就等于msfdb init 和msfconsole)Metasploit指令search ms17_010 会列出许多模..._msf war包部署 渗透
python实战:将cookies添加到requests.session中实现淘宝的模拟登录_浏览器登录淘宝后使用其cookie再用requests登录-程序员宅基地
文章浏览阅读1.4w次,点赞11次,收藏89次。将cookies添加到requests.session中实现淘宝的模拟登录声明:本文仅供学习用,旨在分享我们知道现在爬取淘宝商品是必须要登录的,在没有登录的情况下搜索商品也会自动重定向到登录页面。之前学着用selenium,pyppeteer等自动化框架模拟登录淘宝,但是无论怎么滑动滑块验证都失败。然而就像星爷《新喜剧之王》中所说得:只要不投降就是成功,同时为了安慰自己受伤的小心灵,决定用co..._浏览器登录淘宝后使用其cookie再用requests登录
[NLP]使用LDA模型计算文档相似度_lda关键词提取怎么和文本进行相似度-程序员宅基地
文章浏览阅读1.6w次,点赞2次,收藏68次。定义wiki关于lda的定义:隐含狄利克雷分布简称LDA(Latent Dirichlet allocation),是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。同时它是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可。此外LDA的另一个优点则是,对于每一个主题均可找出一些词语来描述它。LDA首先由Blei, David M.、_lda关键词提取怎么和文本进行相似度
python数据分析报告_Python一行命令生成数据分析报告-程序员宅基地
文章浏览阅读80次。一般在python进行数据分析/统计分析时,第一步总是对数据进行一些描述性分析、相关性分析,但是总会是有一大堆代码,那么今天就介绍一个神器pandas_profiling,一行命令就能搞定大部分描述性分析!安装pip install pandas_profiling使用那么我们继续使用之前文章中使用过很多次的NBA数据集,还记得我们在介绍pandas使用的那篇文章中分很多章节去讲解如何使用pand..._python生成数据分析报告
‘Three-Phase V-I Measurement/Vabc‘ has unapplied changes. Please apply or cancel these changes.-程序员宅基地
文章浏览阅读415次,点赞10次,收藏9次。复制一个这个模块,把原来的模块删除,解决了。_has unapplied changes. please apply or cancel these changes before running t