五分钟了解机器学习的基本概念-程序员宅基地
技术标签: 基于matlab的机器学习 机器学习 人工智能
目录
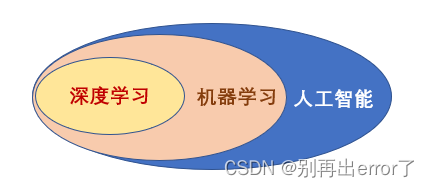
1、人工智能、机器学习、深度学习之间的关系
总的来说,深度学习时机器学习的一个子类,而机器学习又是人工智能的一个子类。
人工智能是一个非常宽泛的概念,它可以代指任何形式的蕴含某些智能特性的技术,并非特指某一特定技术领域。而机器学习则指一个特定领域,用于指代人工智能的一个特定类别。而进一步的,机器学习也包含很多技术,深度学习就是其中之一。
2、什么是机器学习?
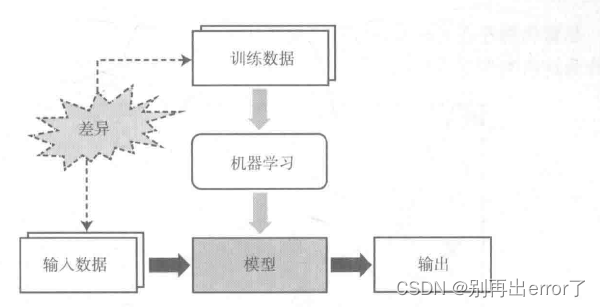
简单地说,机器学习其实就是一种对数据的建模技术,(就我个人看来也像是一种数据处理的算法模型),是一种从数据抽象出模型的技术。数据可以是各种信息,如文档、图像等等,模型就是机器学习的产物。
//就我个人的理解来看,机器学习就是通过海量的数据集合,来对你所建立的模型进行训练,使其达到一个预期的效果,最终生成一个可靠的模型。
 在完成一个模型的建模之后,可以完成推理。(即根据新的数据输入,通过模型后得到一个输出)。而训练数据和输入数据之间存在的差异是机器学习面临的结构下挑战,也是一切问题的根源。
在完成一个模型的建模之后,可以完成推理。(即根据新的数据输入,通过模型后得到一个输出)。而训练数据和输入数据之间存在的差异是机器学习面临的结构下挑战,也是一切问题的根源。
机器学习无法基于错误的训练数据来实现预期目标,就像给新生的婴儿几个苹果,一会儿告诉你是苹果,一会儿告诉你是梨子,一会儿又说是西瓜,他永远不会知道到底什么是苹果。所以,获取能够充分反应实际领域据特征的无偏训练数据至关重要。
这里需要提到一个概念,泛化(generalization):确保模型对于训练数据与输入数据能够获得一致性能的处理过程。机器学习能否成功很大程度上取决于泛化的有效程度。
3、机器学习的常见问题之 过拟合
泛化过程失效的主要诱因之一就是 过拟合。这是一个训练模型时十分常见的问题。下面举一个例子进行简单的描述。
例如,我们需要利用机器学习对两类数据点进行分类。我们以两类数据的特征坐标画出一幅散点图:
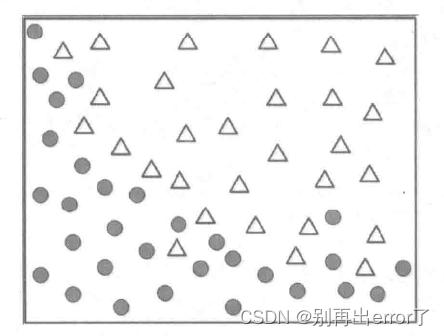
此时我们需要建立一个模型对两者进行分类,实际上也就是得到一条区分两者的边界
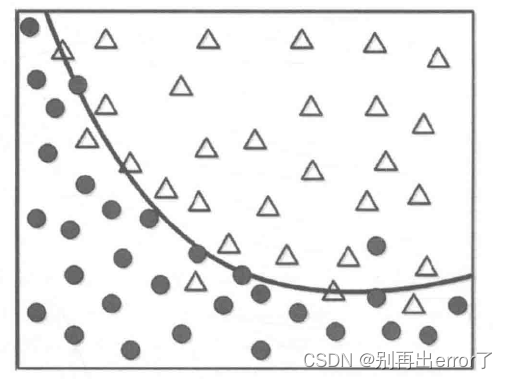
如图所示,虽然存在一定的数据点偏离,但曲线似乎是一条比较合理的边界。
如果我们要以完美的边界对所有数据点进行划分呢?能否正确地反映普适的行为特征呢?
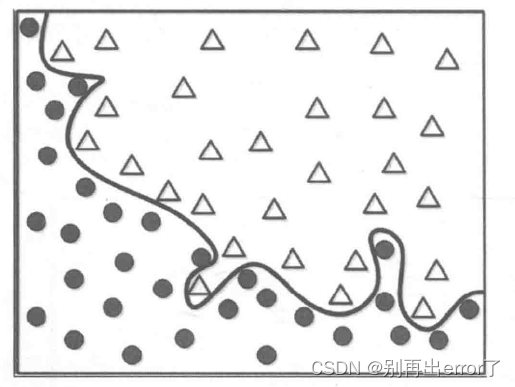
完美的边界如上图所示,针对这样的模型,如果有一个新的数据(正方形)输入,能否得到一个准确的划分呢?
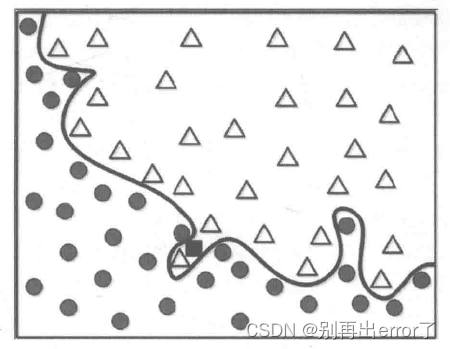
这个完美的边界模型将黑色方形划分为△,但实际上它应该属于黑色圆更加合理,为什么对训练数据的100%准确率匹配会产生问题呢?
其实,在大量的训练数据中,存在的大量的噪声,就比如上述的一些偏离了的数据点。但机器学习无法区分噪声,如果过分要求区分所有训练集数据,他将会生成一个不合理的模型,而对后续所需要判定的实际数据的判定产生误差。
如果认为训练数据中的每一个元素都是准确的,并且精准匹配模型,这将会得到一个普适性较低的模型,这就是过拟合。就比如,你拿出三个苹果,十分强硬地和婴儿宝宝说这就是苹果,其他的就算很像也不是苹果,只有这三个才是苹果。这样,如果再拿来一个新的没有见过的苹果,婴儿宝宝也会觉得这个东西不是刚见过的苹果,所以判断失误,这其实就是过拟合的概念。
4、如何克服过拟合?
这里介绍两种克服过拟合问题的典型方法:正则化和验证。
(1)正则化:是一种力求构建极简模型的数值方法。精简后的模型能以较小的性能代价,避免过拟合的影响。类似于前文讨论的例子,复杂的曲线更倾向于过拟合。而简单的曲线虽然未能正确划分部分数据点,但能更加好的反映总体特征。
(2)验证:验证是指预留一部分训练数据,并利用其监控模型性能的过程。验证数据集不参与训练过程。如果训练过程所生成的模型对预留输入数据的处理效果不佳,则认为存在过拟合。
验证的方法十分常见,也拿之前说的认识苹果来说,相当于你在教婴儿“这2个是苹果”之后,再拿出另一个苹果出来,如果婴儿宝宝能认出来也是苹果,说明教的效果好,反之如果不认识,那就是过拟合的意思了。
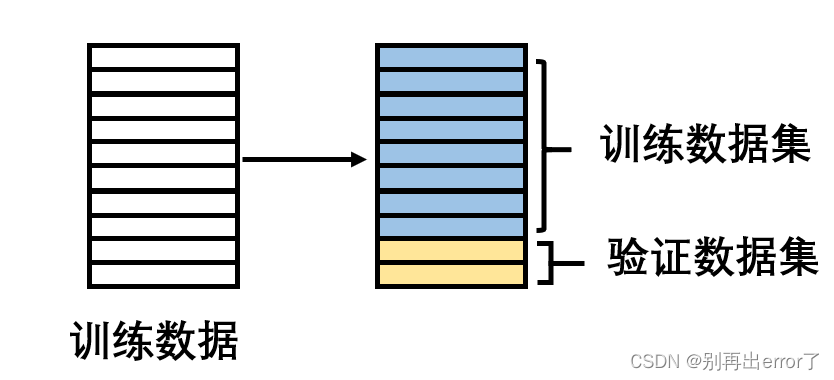
在利用验证技术的机器学习过程包括以下几步:
(1)将训练数据分为两组:一组用于训练,另一组用于验证。根据经验规律,训练数据与验证数据的比例为8:2;
(2)使用训练数据对模型进行训练;
(3)利用验证数据评估模型效果。如果效果满意。结束训练;如果效果不显著,修改模型重新进行训练。
这里再介绍一种验证方法——交叉验证
简单的说,交叉验证就是不保留数据的原始划分,而是重复划分数据。比例一定,但数据划分范围不同,是从训练过程中随机选出的。
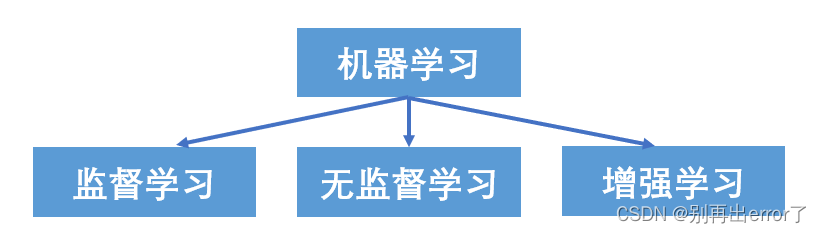
5、机器学习的类型
主要分以下三个大类:
监督学习的应用最为广泛。在监督学习中,每个训练数据集均由输入与标准输出构成的数据对构成。标准输出是模型对该输入应生成的预期结果。
{ input , correct output }
类似于之前的教婴儿认识苹果,苹果这个物体就是数据,它包含苹果的各种特征,比如颜色、大小、触感等等,对用的输出结果就是苹果,婴儿需要学会通过大脑收集到的信息对其进行判断。这就是监督学习。
而在无监督学习中,训练数据仅包含输入,而不包含标准输出。
{ input }
无监督学习通常用于分析数据的特征,并对数据进行预处理。再类比于教婴儿学习苹果,无监督学习相当于没有人告诉宝宝啥是苹果和梨子,而是把一堆水果塞给宝宝,让他自己根据特征分出两个种类,这个过程就相当于提取物体的关键特征。
增强学习利用输入、某些输出以及评分组成的数据集作为训练数据。它通常用在需要优化折中的情况,例如控制和博弈问题。
{ input,some output, grade for this output }
6、分类和回归
监督学习最常见的两类应用就是分类(classification)和回归(regression)。
分类可以说是最主流的应用了,它所关注的就是寻找数据所属的类别。比如数字识别、面部识别等等。类似的,分类问题的训练数据如下
{ input , class} //class 种类即对应这数据的标准输出。
回归不判定类别,而是预测数值。针对对以后数据的学习,得到一个模型,可对新输入的数据进行值的预测。比如天气预测、股票预测等等。
总之,分类是分析研究利用模型来判别输入数据属于哪一种类别;回归是分析利用模型来估计数据的趋势。
DONEDONEDONE!!!

智能推荐
HTTP keep-alive详解_http keepalived-程序员宅基地
文章浏览阅读7.6w次,点赞57次,收藏204次。1.为什么要有Connection: keep-alive?在早期的HTTP/1.0中,每次http请求都要创建一个连接,而创建连接的过程需要消耗资源和时间,为了减少资源消耗,缩短响应时间,就需要重用连接。在后来的HTTP/1.0中以及HTTP/1.1中,引入了重用连接的机制,就是在http请求头中加入Connection: keep-alive来告诉对方这个请求响应完成后不要关闭,下一次咱们还用这_http keepalived
abaqus-程序员宅基地
文章浏览阅读540次。abaqus实验环境:rhel5.5 selinux是disabled iptables offdesktop24.example.com简介:ABAQUS分布式并行计算(Linux系统)一般而言,ABAQUS并行计算有两种模式:(1) 本地并行:利用同一台计算机的多个处理器进行计算。(2) 分布并行:利用相互连接的多台计算机进行计算,而每台..._abaqus分布式并行计算
内网渗透-权限维持-Windows系统隐藏账户_net user test test123! /add-程序员宅基地
文章浏览阅读696次。内网渗透-权限维持-Windows系统隐藏账户通过建立隐藏账户,制作系统用户远程控制后门,维持Windows系统权限。手法步骤1.首先打开cmd,通过命令,创建一个名为test$的隐藏账户,并且把该隐藏账户提升为了管理员权限。net user test$ test123! /addnet localgroup administrators test$ /add2.使用net..._net user test test123! /add
tomcat 多实例部署_-dtomcat.http.port-程序员宅基地
文章浏览阅读1.2k次。如何以Tomcat多实例方式部署多个项目,以下以实例讲解:情景:在linux系统部署两个项目video和navigator。步骤:1.新建目录:/home/hm/apps/2.tomcat安装包apache-tomcat-8.0.26.tar.gz解压缩到目录/home/hm/apps/apache-tomcat-8.0.263.新建目录/home/hm/apps/tomc_-dtomcat.http.port
如何搭建个人博客网站【图/文教程】_个人博客网站搭建-程序员宅基地
文章浏览阅读6.1k次,点赞2次,收藏41次。1.Emlog博客系统(我使用的是这个,轻量级,占用资源少,上手非常简单,推荐新手使用) 官网:https://www.emlog.net/2.ZBlog博客程序 (这款程序当年挺火的,国人开发,我以前也用过,还不错) 官网:https://www.zblogcn.com/3.typecho博客程序(这款程序近期是挺火的,很多人用来发布日记,日志,生活等等。网上也挺多好看的模板,喜欢的话可以尝试搭建一下) 官网:http://typecho.org/_个人博客网站搭建
软件设计师-计算机基础复习7-计算机系统结构分类-程序员宅基地
文章浏览阅读4k次。计算机系统机构分类
随便推点
“blp673是一款什么型号的手机?编程指南“_model:blp673-程序员宅基地
文章浏览阅读135次。总之,blp673是一款功能强大的智能手机,它不仅具备先进的硬件性能,还支持用户进行编程操作。blp673是一款新型号的智能手机,它具有强大的硬件性能和丰富的软件功能。它搭载了最新的处理器和操作系统,为用户提供流畅的使用体验。此外,blp673还拥有高分辨率的显示屏、优秀的摄像头和大容量的存储空间,以满足用户对于多媒体和游戏的需求。除了强大的硬件性能,blp673还提供了丰富的软件功能,允许用户进行编程操作。这个简单的程序展示了blp673手机上的编程能力,用户可以根据自己的需求进行更复杂的编程操作。_model:blp673
解决HBase整合Hive时一直连接地址为localhost2181的zookeeper的问题_hbase单机版 2181无法访问-程序员宅基地
文章浏览阅读1.7k次。解决HBase整合Hive时一直连接地址为localhost:2181的zookeeper的问题问题描述我在搭建HBase集群整合hive的时候,hive一直连接本地的zookeeper,而不是连接HBase集群中配置的zk地址1.HBase起初以为HBase中hbase-env.sh 这个配置没有生效,export HBASE_MANAGES_ZK=false反复检查了配置,应该是没有问题2.Hive检查hive中的zookeeper,也是没有问题的。最后发现hbase.zookee_hbase单机版 2181无法访问
VM中离线安装Ubuntu22.04系统_ubuntu server 22.04 离线-程序员宅基地
文章浏览阅读530次。内存设置2G此处网络适配器中的设备状态的两个方框都不要打钩。_ubuntu server 22.04 离线
Python3 http服务器脚本,支持range请求头部(因此可以用它来在线看mp4视频)-程序员宅基地
文章浏览阅读2.9k次。# -*- coding: gbkimport http.serverimport timeimport socketserverimport osimport threadingimport socket#下面的导入从SimpleHTTPServer.py复制:import posixpathimport urllib.parseimport cgiimport sys
Axis2/c 知识点-程序员宅基地
文章浏览阅读145次。官网文档: http://axis.apache.org/axis2/c/core/docs/axis2c_manual.html从文档中可以总结出:1. Axis2/C是一个用C语言实现的Web Service引擎。Axis2/C基于Axis2架构,支持SOAP1.1和SOAP1.2协议,并且支持RESTful风格的Web Service。基于Axis2/C的Web Service可以..._axis2/c服务端调用axis2_get_instance
企业架构方法论-程序员宅基地
文章浏览阅读3k次。目前主要的两种架构方法(准确的说是方法论),具体的方法也是有的,也有可实际操作层面的东西,那要看很多的各个细分专业层面的东西。比如画流程图,业务流程图、数据流程图、系统交互流程图等等。togafzachmanzachman业务建模分析框架,相比于togaf,直观上直接提供了可操作的东西,可能大家更容易接受一些。这里推荐一个架构设计的专业工具,是免费的,即ArchMateArchi – Open Source ArchiMate Modelling (archim..._企业架构方法论